Consider the program example in Section 1. The curry2prolog compiler of PAKCS [2] produces the following set of rules (clauses), as a result of the compilation of the original program (written in Curry - see next section):
f(A,B,C) :- hnf(A,F), f_1(F,B,C).
f_1(a,A,B) :- hnf(A,E), f_1_a_1(E,B).
f_1_a_1(a,a).
g(A,B) :- hnf(A,E), g_1(E,B).
g_1(a,a).
g_1(b,b).
Now, f(A,B,C) is a predicate where A and B are input
arguments and C is an output argument which returns the result of
a computation, and there is a close correspondence
with the previous simple uniform
program. This means that the
left-to-right selection strategy of Prolog exploits the inductive positions
of
The equivalence between needed narrowing and uniform lazy narrowing suggests
the following improvement in the implementations of needed narrowing, where
the original program is compiled into a ``uniform-like'' set of clauses which
are run in the Prolog implementation also. Now, the rule defining the function
![]() in the program of Section 1 can be compiled into the following
set of Prolog clauses:
in the program of Section 1 can be compiled into the following
set of Prolog clauses:
imf(A,B,C) :- hnf(A,F),hnf(B,G),imf_1(F,G,C).
imf_1(a,a,a).
Let us notice that uniform clauses may require an extra pattern-matching effort,
in comparison with the corresponding simple uniform rules.
In a experimental evaluation of the method, we have measured a speedup of 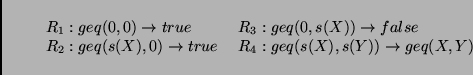
vobeyspacesimgeq(A,B,C):-hnf(A,F), hnf(B,G), imgeq_1(F,G,C).
imgeq_1(zero,zero,'True').
imgeq_1(zero,succ(_),'False').
imgeq_1(succ(_),zero,'True').
imgeq_1(succ(A),succ(B),C):- imgeq(A,B,C).
For this last example and input term
![]() , we
obtain a speedup of
, we
obtain a speedup of ![]() .
.